 25/01/2022 - Ao usar hiperredes, os pesquisadores agora podem ajustar preventivamente as redes neurais artificiais, economizando tempo e despesas de treinamento. A inteligência artificial é em grande parte um jogo de números. Quando as redes neurais profundas, uma forma de IA que aprende a discernir padrões nos dados, começaram a superar os algoritmos tradicionais há 10 anos, foi porque finalmente tínhamos dados e poder de processamento suficientes para fazer pleno uso deles.
25/01/2022 - Ao usar hiperredes, os pesquisadores agora podem ajustar preventivamente as redes neurais artificiais, economizando tempo e despesas de treinamento. A inteligência artificial é em grande parte um jogo de números. Quando as redes neurais profundas, uma forma de IA que aprende a discernir padrões nos dados, começaram a superar os algoritmos tradicionais há 10 anos, foi porque finalmente tínhamos dados e poder de processamento suficientes para fazer pleno uso deles.
As redes neurais de hoje estão ainda mais famintas por dados e energia. Treiná-los requer um ajuste cuidadoso dos valores de milhões ou mesmo bilhões de parâmetros que caracterizam essas redes, representando os pontos fortes das conexões entre neurônios artificiais. O objetivo é encontrar valores quase ideais para eles, processo conhecido como otimização, mas treinar as redes para chegar a esse ponto não é fácil. “O treinamento pode levar dias, semanas ou até meses”, disse Petar Veličković, cientista de pesquisa da DeepMind em Londres.
Isso pode mudar em breve. Boris Knyazev, da Universidade de Guelph, em Ontário, e seus colegas projetaram e treinaram uma “hiperrede” – uma espécie de suserano de outras redes neurais – que poderia acelerar o processo de treinamento. Dada uma nova rede neural profunda não treinada projetada para alguma tarefa, a hiperrede prevê os parâmetros para a nova rede em frações de segundo e, em teoria, poderia tornar o treinamento desnecessário. Como a hiper-rede aprende os padrões extremamente complexos nos projetos de redes neurais profundas, o trabalho também pode ter implicações teóricas mais profundas.
Leia também - Pesquisador húngaro ganha prêmio por procedimento que pode curar a cegueira
Por enquanto, a hiper-rede tem um desempenho surpreendentemente bom em certas configurações, mas ainda há espaço para crescer – o que é natural, dada a magnitude do problema. Se eles puderem resolvê-lo, “isso será bastante impactante para o aprendizado de máquina”, disse Veličković.
Ficando hiper
Atualmente, os melhores métodos para treinar e otimizar redes neurais profundas são variações de uma técnica chamada de gradiente descendente estocástico (SGD). O treinamento envolve minimizar os erros que a rede comete em uma determinada tarefa, como reconhecimento de imagem. Um algoritmo SGD agita muitos dados rotulados para ajustar os parâmetros da rede e reduzir os erros ou perdas. A descida do gradiente é o processo iterativo de descer de valores altos da função de perda para algum valor mínimo, que representa valores de parâmetros suficientemente bons (ou às vezes até os melhores possíveis).
Mas essa técnica só funciona quando você tem uma rede para otimizar. Para construir a rede neural inicial, normalmente composta por várias camadas de neurônios artificiais que levam de uma entrada a uma saída, os engenheiros devem confiar em intuições e regras práticas. Essas arquiteturas podem variar em termos de número de camadas de neurônios, número de neurônios por camada e assim por diante.
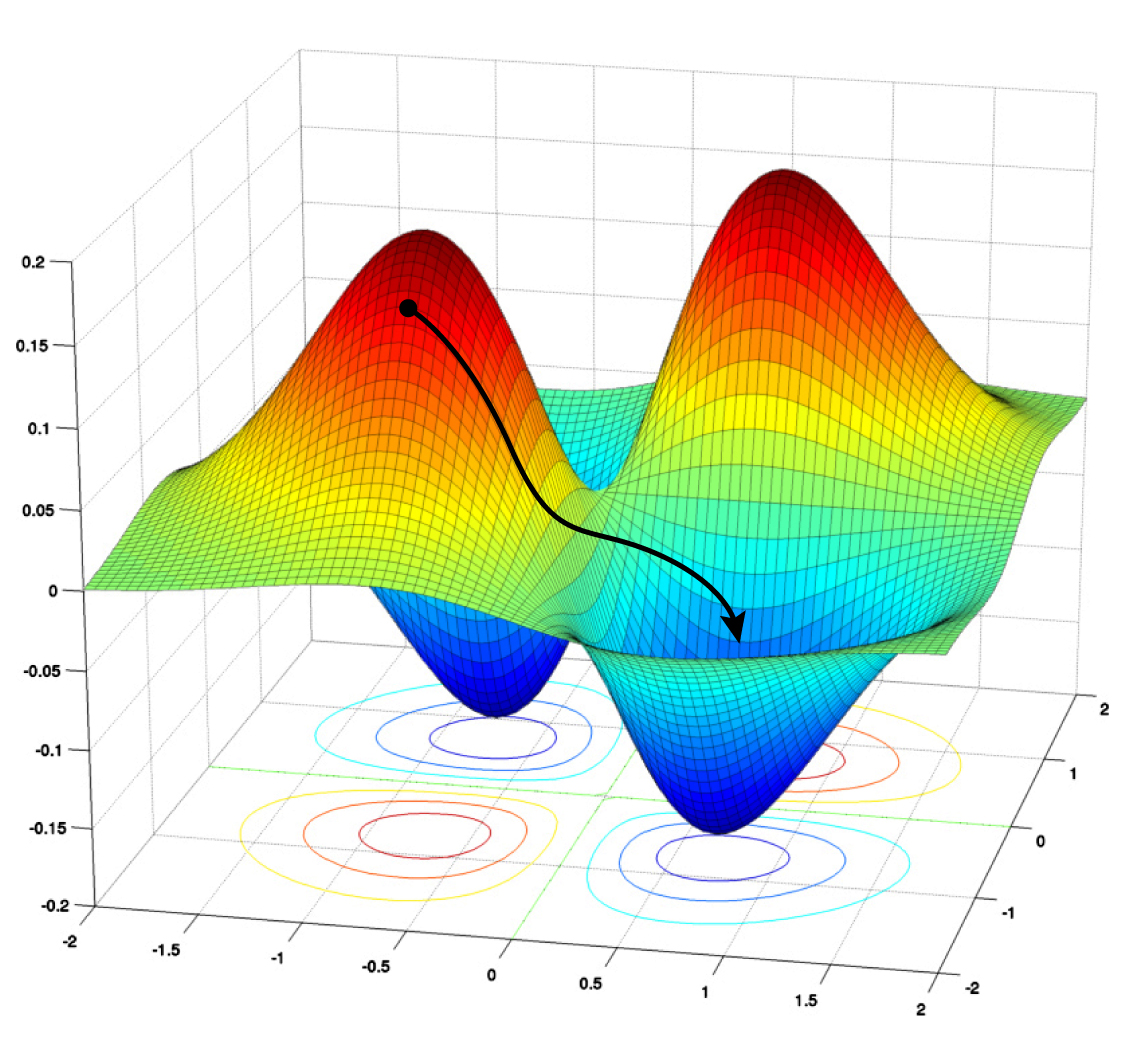
A descida do gradiente leva uma rede para baixo em seu “cenário de perdas”, onde valores mais altos representam maiores erros ou perdas. O algoritmo tenta encontrar o valor mínimo global para minimizar a perda.
Pode-se, em teoria, começar com muitas arquiteturas, depois otimizar cada uma e escolher a melhor. “Mas o treinamento [leva] uma quantidade de tempo bastante não trivial”, disse Mengye Ren, agora pesquisador visitante do Google Brain. Seria impossível treinar e testar todas as arquiteturas de rede candidatas. “[Não] escala muito bem, especialmente se você considerar milhões de projetos possíveis.”
Então, em 2018, Ren, junto com seu ex-colega da Universidade de Toronto Chris Zhang e sua conselheira Raquel Urtasun, tentaram uma abordagem diferente. Eles projetaram o que chamaram de hiperrede gráfica (GHN) para encontrar a melhor arquitetura de rede neural profunda para resolver alguma tarefa, dado um conjunto de arquiteturas candidatas.
Leia também - Robô “vampiro” médico procura veia humana, insere agulha e suga sangue
O nome descreve sua abordagem. “Gráfico” refere-se à ideia de que a arquitetura de uma rede neural profunda pode ser pensada como um gráfico matemático – uma coleção de pontos, ou nós, conectados por linhas ou arestas. Aqui, os nós representam unidades computacionais (geralmente, uma camada inteira de uma rede neural) e as arestas representam a maneira como essas unidades estão interconectadas.
Aqui está como funciona. Uma hiper-rede gráfica começa com qualquer arquitetura que precise ser otimizada (vamos chamá-la de candidata). Em seguida, ele faz o possível para prever os parâmetros ideais para o candidato. A equipe então define os parâmetros de uma rede neural real para os valores previstos e a testa em uma determinada tarefa. A equipe de Ren mostrou que esse método pode ser usado para classificar arquiteturas candidatas e selecionar a de melhor desempenho.
Quando Knyazev e seus colegas encontraram a ideia da hiper-rede gráfica, eles perceberam que poderiam construir sobre ela. Em seu novo artigo, a equipe mostra como usar GHNs não apenas para encontrar a melhor arquitetura de um conjunto de amostras, mas também para prever os parâmetros para a melhor rede, de modo que ela tenha um bom desempenho em um sentido absoluto. E em situações em que o melhor não é bom o suficiente, a rede pode ser treinada ainda mais usando gradiente descendente.
“É um papel muito sólido. [Ele] contém muito mais experimentação do que o que fizemos”, disse Ren sobre o novo trabalho. “Eles trabalham muito duro para aumentar o desempenho absoluto, o que é ótimo de ver.”
Treinando o Treinador
Knyazev e sua equipe chamam sua hiper-rede de GHN-2, e ela melhora dois aspectos importantes da hiper-rede gráfica construída por Ren e colegas.
Primeiro, eles confiaram na técnica de Ren de representar a arquitetura de uma rede neural como um gráfico. Cada nó no gráfico codifica informações sobre um subconjunto de neurônios que fazem algum tipo específico de computação. As arestas do gráfico descrevem como a informação flui de nó para nó, da entrada para a saída.
A segunda ideia que eles usaram foi o método de treinamento da hiper-rede para fazer previsões para novas arquiteturas candidatas. Isso requer duas outras redes neurais. O primeiro permite cálculos no grafo candidato original, resultando em atualizações nas informações associadas a cada nó, e o segundo recebe os nós atualizados como entrada e prevê os parâmetros para as unidades computacionais correspondentes da rede neural candidata. Essas duas redes também têm seus próprios parâmetros, que devem ser otimizados antes que a hiper-rede possa prever corretamente os valores dos parâmetros.
Para fazer isso, você precisa de dados de treinamento — nesse caso, uma amostra aleatória de possíveis arquiteturas de rede neural artificial (ANN). Para cada arquitetura na amostra, você começa com um gráfico e, em seguida, usa a hiper-rede de gráficos para prever parâmetros e inicializar a RNA candidata com os parâmetros previstos. A RNA então realiza alguma tarefa específica, como reconhecer uma imagem. Você calcula a perda feita pela ANN e, em vez de atualizar os parâmetros da ANN para fazer uma previsão melhor, atualiza os parâmetros da hiper-rede que fez a previsão em primeiro lugar. Isso permite que a hiper-rede tenha um desempenho melhor na próxima vez. Agora, itere sobre cada imagem em algum conjunto de dados de treinamento rotulado de imagens e cada ANN na amostra aleatória de arquiteturas, reduzindo a perda em cada etapa, até que não possa fazer melhor. Em algum momento, você acaba com uma hiper-rede treinada.
A equipe de Knyazev pegou essas ideias e escreveu seu próprio software do zero, já que a equipe de Ren não divulgou seu código-fonte. Então Knyazev e seus colegas melhoraram. Para começar, eles identificaram 15 tipos de nós que podem ser misturados e combinados para construir quase qualquer rede neural profunda moderna. Eles também fizeram vários avanços para melhorar a precisão da previsão.
Mais significativamente, para garantir que o GHN-2 aprenda a prever parâmetros para uma ampla variedade de arquiteturas de rede neural alvo, Knyazev e colegas criaram um conjunto de dados exclusivo de 1 milhão de arquiteturas possíveis. “Para treinar nosso modelo, criamos arquiteturas aleatórias [que são] as mais diversas possíveis”, disse Knyazev.
Como resultado, é mais provável que a proeza preditiva do GHN-2 generalize bem para arquiteturas de destino invisíveis. “Eles podem, por exemplo, explicar todas as arquiteturas típicas de última geração que as pessoas usam”, disse Thomas Kipf, pesquisador do Brain Team do Google Research em Amsterdã. “Essa é uma grande contribuição.”
Resultados impressionantes
O verdadeiro teste, é claro, foi colocar o GHN-2 para funcionar. Depois que Knyazev e sua equipe o treinaram para prever parâmetros para uma determinada tarefa, como classificar imagens em um conjunto de dados específico, eles testaram sua capacidade de prever parâmetros para qualquer arquitetura candidata aleatória. Esse novo candidato pode ter propriedades semelhantes às milhões de arquiteturas no conjunto de dados de treinamento ou pode ser diferente – um pouco atípico. No primeiro caso, diz-se que a arquitetura de destino está em distribuição; no último, está fora de distribuição. As redes neurais profundas geralmente falham ao fazer previsões para o último, portanto, testar o GHN-2 nesses dados era importante.
Armado com um GHN-2 totalmente treinado, a equipe previu parâmetros para 500 arquiteturas de rede de destino aleatório nunca vistas anteriormente. Em seguida, essas 500 redes, seus parâmetros definidos para os valores previstos, foram comparadas às mesmas redes treinadas usando gradiente descendente estocástico. A nova hiper-rede muitas vezes resistiu a milhares de iterações do SGD e, às vezes, se saiu ainda melhor, embora alguns resultados fossem mais mistos.
Para um conjunto de dados de imagens conhecido como CIFAR-10, a precisão média do GHN-2 em arquiteturas em distribuição foi de 66,9%, o que se aproximou da precisão média de 69,2% alcançada por redes treinadas usando 2.500 iterações de SGD. Para arquiteturas fora de distribuição, o GHN-2 se saiu surpreendentemente bem, alcançando cerca de 60% de precisão. Em particular, alcançou uma precisão respeitável de 58,6% para uma arquitetura de rede neural profunda bem conhecida chamada ResNet-50. “A generalização para o ResNet-50 é surpreendentemente boa, já que o ResNet-50 é cerca de 20 vezes maior do que nossa arquitetura de treinamento média”, disse Knyazev, falando no NeurIPS 2021, o principal encontro do campo.
O GHN-2 não se saiu tão bem com o ImageNet, um conjunto de dados consideravelmente maior: em média, teve apenas cerca de 27,2% de precisão. Ainda assim, isso se compara favoravelmente com a precisão média de 25,6% para as mesmas redes treinadas usando 5.000 etapas de SGD. (É claro que, se você continuar usando o SGD, poderá eventualmente – a um custo considerável – acabar com 95% de precisão.) Mais importante, o GHN-2 fez suas previsões do ImageNet em menos de um segundo, enquanto o uso do SGD para obter o mesmo desempenho já que os parâmetros previstos demoraram, em média, 10.000 vezes mais em sua unidade de processamento gráfico (o cavalo de batalha atual do treinamento de redes neurais profundas).
“Os resultados são definitivamente super impressionantes”, disse Veličković. “Eles basicamente reduzem significativamente os custos de energia.”
E quando o GHN-2 encontra a melhor rede neural para uma tarefa a partir de uma amostra de arquiteturas, e essa melhor opção não é boa o suficiente, pelo menos o vencedor agora está parcialmente treinado e pode ser otimizado ainda mais. Em vez de desencadear o SGD em uma rede inicializada com valores aleatórios para seus parâmetros, pode-se usar as previsões do GHN-2 como ponto de partida. “Essencialmente, imitamos o pré-treinamento”, disse Knyazev.
Além do GHN-2
Apesar desses sucessos, Knyazev acredita que a comunidade de aprendizado de máquina a princípio resistirá ao uso de hiper-redes gráficas. Ele compara isso à resistência enfrentada pelas redes neurais profundas antes de 2012. Naquela época, os praticantes de aprendizado de máquina preferiam algoritmos projetados à mão em vez das misteriosas redes profundas. Mas isso mudou quando redes profundas massivas treinadas em grandes quantidades de dados começaram a superar os algoritmos tradicionais. “Isso pode seguir o mesmo caminho.”
Enquanto isso, Knyazev vê muitas oportunidades de melhoria. Por exemplo, o GHN-2 só pode ser treinado para prever parâmetros para resolver uma determinada tarefa, como classificar imagens CIFAR-10 ou ImageNet, mas não ao mesmo tempo. No futuro, ele imagina treinar hiperredes de grafos em uma maior diversidade de arquiteturas e em diferentes tipos de tarefas (reconhecimento de imagem, reconhecimento de fala e processamento de linguagem natural, por exemplo). Em seguida, a previsão pode ser condicionada tanto à arquitetura de destino quanto à tarefa específica em questão.
E se essas hiper-redes decolarem, o design e o desenvolvimento de novas redes neurais profundas não estarão mais restritos a empresas com bolsos profundos e acesso a big data. Qualquer um poderia entrar no ato. Knyazev está bem ciente desse potencial de “democratizar o aprendizado profundo”, chamando-o de visão de longo prazo.
No entanto, Veličković destaca um problema potencialmente grande se hiperredes como GHN-2 se tornarem o método padrão para otimizar redes neurais. Com hiper-redes gráficas, ele disse, “você tem uma rede neural – essencialmente uma caixa preta – prevendo os parâmetros de outra rede neural. Então, quando comete um erro, você não tem como explicar [isso].”
Claro, isso já é amplamente o caso das redes neurais. “Eu não chamaria isso de fraqueza”, disse Veličković. “Eu chamaria isso de um sinal de alerta.”
Leia também - O Google está trabalhando em tatuagens que transformam seu corpo em um touchpad
Kipf, no entanto, vê um lado bom. “Algo [mais] me deixou mais empolgado com isso.” O GHN-2 mostra a capacidade das redes neurais gráficas de encontrar padrões em dados complicados.
Normalmente, as redes neurais profundas encontram padrões em imagens ou sinais de texto ou áudio, que são tipos de informações bastante estruturados. O GHN-2 encontra padrões nos gráficos de arquiteturas de redes neurais completamente aleatórias. “São dados muito complicados.”
E, no entanto, o GHN-2 pode generalizar - o que significa que pode fazer previsões razoáveis de parâmetros para arquiteturas de rede invisíveis e até mesmo fora de distribuição. “Este trabalho nos mostra que muitos padrões são semelhantes em diferentes arquiteturas, e um modelo pode aprender como transferir conhecimento de uma arquitetura para outra”, disse Kipf. “Isso é algo que pode inspirar uma nova teoria para redes neurais.”
Se for esse o caso, pode levar a uma nova e maior compreensão dessas caixas pretas.
Fonte: https://www.quantamagazine.org/